검색 후 2페이지 가면 에러가 났었다(한글URL 문제)
오늘 우연히 듣게 된 사실, 인터넷 익스플로러(6~8까지 모두 다)에서 검색을 한 후 페이지를 넘기면 페이지가 깨지는 문제가 있었다는 것. 아래 그림처럼 말이다.
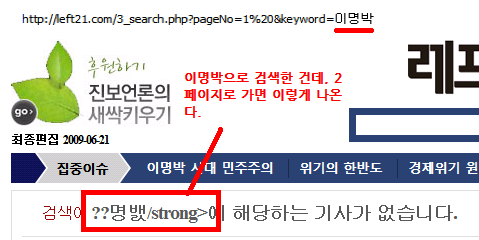
보다시피 이명박이라는 주소표시줄 글자가 처참하게 깨진 채로 화면에 나온다.
익스플로러의 문제
간단히 말해 익스플로러의 문제다. (기사 검색을 많이 하는 레프트21 기자들은 전원 파이어폭스를 사용하기 때문에 문제를 발견할 수 없었을 것이다. 비용 문제 때문에 레프트21 사무실은 리눅스를 사용한다.)
익스플로러는 URL 주소 표시줄에 사용하는 한글 처리 방식이, UTF-8이 아니다. 그런데 HTML에서 보내주는 건 UTF-8 방식이다.
쉽게 설명하자면 이렇다. 컴퓨터는 글자를 숫자로 표현한다. 예컨대, 영문 M은 16진수 4D에 해당한다. 영문은 몇 자 안 되기 때문에 간단히 숫자로 표현할 수 있었다. 그런데 한글 등 다른 문자들은 아니었다.(심지어 한자! ㅠ.ㅠ) 그런데 문제는 처음에 영어를 숫자로 표현한 사람들이, 이걸 염두에 두지 않았던 것이다.
euc-kr은 나름대로 처음 방식을 활용해서 만든 한글 인코딩 방식인데, 이렇게 하면 2350자의 한글만 표현할 수 있다. 이렇게 말하면 많아 보이겠지만, 모든 현대 한글을 제대로 표현할 수 있는 것은 아니다.(방금 시험해 봤는데 euc-kr도 아햏햏이나 뷁 같은 낱말은 쓸 수 있다.)
전세계의 모든 언어를 표현할 수 있도록 문자 인코딩 방식을 표준화한 것이 UTF방식이다. 8비트인 UTF-8 방식와 16비트인 UTF-16 방식으로 나뉜다고 하는데, 어떤 차이가 있는지는 모르겠다.
자, 그럼, 우리는 이제 이런 걸 알 수 있게 된다. 레프트21 홈페이지는 UTF-8 방식으로 인코딩돼 있다. 익스플로러의 주소표시줄은 UTF-8 방식을 지원하지 않는다. 즉, 만약 UTF-8이 ‘박’이라는 의미로 5555을 주소 표시줄에 보냈다고 하자, 그러면 익스플로러는 이걸 ‘밼’으로 알아먹을 수도 있게 된다는 거다.
해결책은?
그래서, 해결책은 없는 것인가? 걱정할 거 없다. 고쳤다.
어떻게 고쳤는가? 궁금하신 개발자들을 위해 간단히 말한다면, encodeurl($str) 함수를 사용했다. 자세한 내용은 다음 문서를 참고하면 된다. URL 인코딩에 대한 자세한 정보가 있는 문서다 : [PHP] urlencode(), base64_encode() 함수
그래서 아래처럼 됐다.
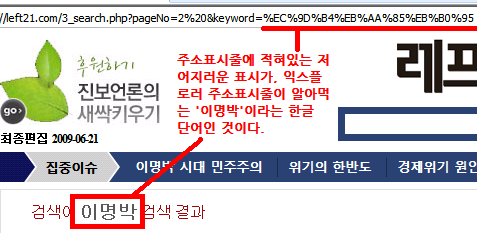
오류 신고가 절실하다
이번 에러는 지난 번에 자바스크립트로 된 링크를 HTML 링크로 개선해 웹접근성을 강화한 뒤에 생긴 에러가 분명하다. 그게 5월 17일이었으니 대략 한 달 동안 에러가 있었던 것이다. 그런데 아무도 말해 주지 않다가 오늘에서야 듣게 됐다.
사람들이 검색을 많이 안 해서, 이런 오류를 만나지 못했을거라 생각할 수는 없다. 오류 신고 게시판을 적극 활용해 주시라고, 다시 한 번 요청드리며 글을 맺는다.