지난 호 보기 개선, 그리고 효율적(?) 사회 진보
레프트21은 지난 호 보기 서비스를 제공하고 있습니다. 지난 호 보기는 표지 보기와 목록 보기로 나뉘어지죠. 아래 그림을 참고하세요.
△바로 저 위치에서 지난 호 보기 메뉴를 찾을 수 있습니다.
△이건 목록으로 보기 화면이죠.
△이건 표지로 보기 화면입니다.

사실, 우리 신문을 정기적으로 보시는 분들은 지난 호를 찾아 볼 일이 점점 많아질 것입니다. 때로는 검색보다 몇 호 신문이었는지 기억을 떠올려서 바로 그 신문을 찾아보는 게 더 편할 수도 있습니다. 어쩌면 그냥 예전 신문 기사를 하나하나 읽어보고 싶은 새로운 독자가 있을 지도 모르는 일입니다.
그런데, 지난 호 보기의 목록 보기 항목은 속도가 너무나 느렸답니다. ㅠ.ㅠ 그래서 지금 웹사이트를 전반적으로 기획하고 있는 웹마스터인 연두님의 걱정이 이만저만이 아니었어요. “지난 호 보기가 우리 웹사이트의 약점인 것 같다”고 말했었죠.
사실 제가 봐도 그랬습니다. 애초에 웹사이트를 기획할 때 지난 호를 더 쉽게 찾아볼 수 있도록 하기 위해 표지 보기와 목록 보기를 직관적으로 제공하고, 목록 보기에서도 다른 호수로 손쉽게 이동할 수 있도록 아이디어를 짰었는데(왼쪽 그림을 참고하세요) 속도가 느리면 아무 소용 없는 겁니다.
속도가 느린 이유는 간단합니다. 프로그래밍이 잘못 되어 있기 때문입니다. 좀 더 자세히 말하면, 데이터베이스에 접속하는 횟수가 너무 많았기 때문입니다.(무슨 말인지 잘 모를 수도 있을 거라 생각하는데, 이해하려 노력하지 마세요 ^^)
결론부터 얘기하면…
이렇게 변했습니다. 아래 그림을 보세요.
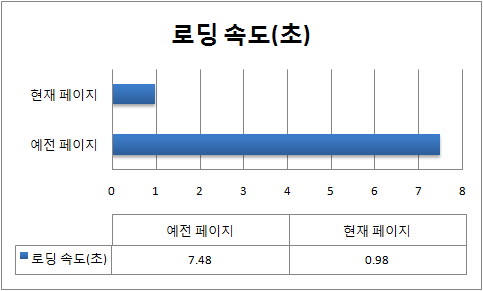
△그래프가 짧은 게 좋은 겁니다.
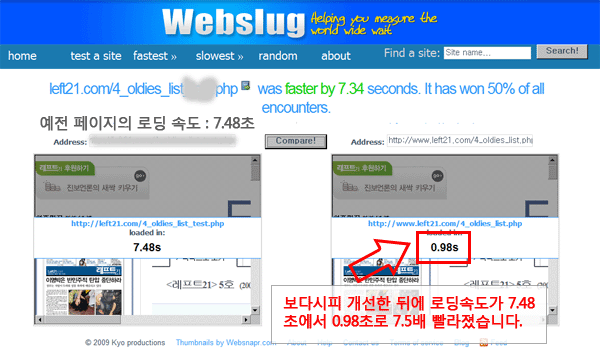
△이건 속도 비교 사이트, www.webslug.info에서 비교한 결과를 캡쳐한 것입니다.
위 그림에서 볼 수 있듯이, 불러오는 데 7.48초나 걸리던 화면이 0.98초밖에 안 걸리게 빨라졌습니다.(임시 인터넷 파일을 모두 삭제하고 잰 것입니다.)
앞으로는 더 쾌적한 환경에서 지난 호 보기를 이용하실 수 있을 겁니다.
기술적 이야기
자, 이 아래로는 기술적인 이야기입니다. 최대한 쉽게 써 보죠. ^^ 이 분야의 상식을 익히고 싶은 분들은 읽어도 됩니다. 그렇지 않은 분들은 읽을 필요가 없습니다.
원래 지난 호 보기 - 목록으로 보기가 느렸던 이유는 간단합니다. 데이터베이스에 무려 10회 정도나 접속하면서 기사 목록을 불러왔기 때문입니다.
무슨 말인지 이해가 안 갈 수 있다고 생각해 그림을 이용해 이해를 돕겠습니다.
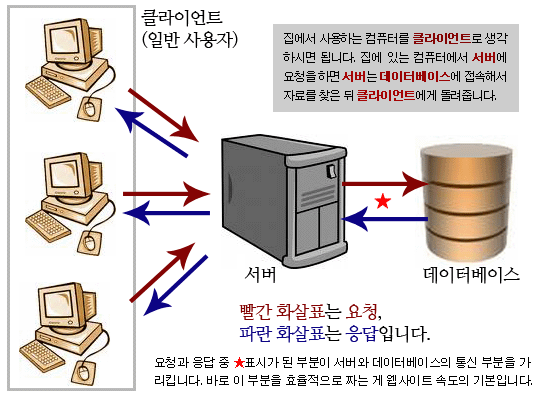
인터넷을 한다는 것은, 기술적으로 간단히 말하면, 서버라고 부르는 컴퓨터에 원격으로 접속해서 그 안의 내용을 읽는 것입니다. 이 서버는 사용자들이 내용을 읽을 수 있도록 안내를 해 주고 자료를 전송해 줍니다. 그런데, 인터넷을 발달하고 다루는 정보의 양이 많아지면서, 서버가 대용량의 정보를 쉽게 분류해서 보내줄 수 있도록 데이터베이스가 만들어졌습니다. 쉽게 생각해서 데이터베이스는 서버에 있는 자료실이라고 생각하면 됩니다.
자, 그래서 레프트21의 자료들도 모두 데이터베이스에 저장돼 있죠. 레프트21이 현재 보유하고 있는 기사는 다 합쳐서 6000개 정도 됩니다. 서버는 이 6000개의 기사 중에 사용자가 요청하는 것을 찾습니다. 어디서 찾느냐? 데이터베이스에서 찾는 거죠. 그래서 그 결과를 사용자의 컴퓨터로 보내주는 것이죠. 그게 서버가 하는 역할입니다.
목록 불러오기
기사 하나를 불러오는 건 쉽고 빠릅니다. 그런데 목록을 불러오는 건 조금 복잡합니다.
데이터베이스에 자료를 저장할 때, 자료 저장의 효율을 생각해서 저장을 해야 합니다. 이걸 위해서 자료를 나누어서 저장합니다. 레프트21처럼 수천 개 정도의 자료만 있는 사이트는 아직 그런 문제가 없겠지만, 은행 같은 데를 생각해 보세요. 고객만 수백 만 명이 될 텐데, 그걸 빠르게 조회하려면 엄청난 일이겠죠.
그래서 아래처럼 데이터를 나눠서 저장을 합니다.<table style=”float: left; margin-right: 20px;” border=1> <caption>
기사 테이블</caption> </table> <table style=”float: left;” border=1 width=200> <caption>기사를 분류하는 테이블</caption> </table>
자, 위의 테이블 두 개를 일단 자세히 보세요. 그래야 아래 설명이 이해됩니다. 기사 목록을 불러올 때 무작위로 불러오지 않고, 기사 분류별로 차례대로 불러온다는 것을 알고 있으시죠? 이걸 해결하려고 예전에는 다음 공식을 따라서 처리했습니다.
▶주요 기사 불러오기 시작 ▶ 1번 기사의 기사 분류를 확인한다 ▶ 주요기사니까 불러온다 ▶ 2번 기사의 기사 분류를 확인한다 ▶ 주요기사가 아니니까 불러오지 않는다 ▶ 3번 기사의 기사 분류를 확인한다 ▶ 주요기사니까 불러온다
▶칼럼 불러오기 시작 ▶ 1번 기사의 기사 분류를 확인한다 ▶ 칼럼이 아니니까 불러오지 않는다 ▶ 2번 기사의 기사 분류를 확인한다 ▶ 칼럼이니까 불러온다 ▶ 3번 기사의 기사 분류를 확인한다 ▶ 칼럼이 아니니까 불러오지 않는다
이해가 되시나요? 레프트21의 기사 분류는 11개나 됩니다.(지금 위에 예시로 간단하게 한 건 분류가 2개인 거죠.) 그리고 한 호당 기사는 60~70개입니다.(위에 간단하게 든 예는 기사가 3개죠?) 즉, 저 과정을 기사 60~70개에 대해 11번 반복하면서 불러온 것입니다.(좀 더 정확히 말하면 메인 기사를 불러오는 알고리즘은 또 따로 있습니다. 그래서 정확히 말하면, 일단 위에서 설명한 것과 비슷한 방법으로 메인을 불러온 뒤, 나머지를 불러오는 11회의 과정을 진행한 것이죠.)
여기에 몇 가지 알고리즘이 더 붙는데 훨씬 복잡해지니까 생략하겠습니다. 어쨌든, 그동안 왜 느렸는지는 대충 이해가 되시나요?
홈페이지에서 시간을 꽤 많이 잡아먹는 부분은 플래시와 DB입니다.(아직까지 제가 알기로는 그렇습니다.) 플래시는 용량이 커서 그렇고, DB는 접속할 때 시간이 걸립니다. 자료가 방대하면 찾는 데도 오래 걸리는 경우가 많고요.(검색에 시간이 좀 걸리는 이유는 이 때문입니다.) 레프트21은 플래시를 사용하지 않습니다. 이걸로 일단 속도를 높이는 데 기여했죠. 그러나 DB에 여러 번 접속을 하는 경우가 많기 때문에 느린 페이지가 몇 개 있습니다.
그리고 바로 어제, 이것을 개선한 것입니다. 11번 반복해서 DB에 접속하고 기사를 불러오는 과정을 1회로 줄였습니다. 그렇기 때문에 이렇게 빨라진 것입니다. (초보 개발자분들을 위해 말씀드리면, OUTER JOIN을 사용했습니다. 궁금하시면 ‘테이블 조인’으로 검색해 보세요.)
효율화
기술 진보는 불필요는 노동을 줄여줍니다. 물론, 이 사회는 기술 진보로 작업이 효율화되면, 그걸로 더 많은 노동을 시킬 생각만 하죠.(일례로 인터넷의 발달은 노동시간을 늘렸습니다. 집에서도 일할 수 있게 됐으니까요.) 그러나 레프트21 같은 진보언론까지 그렇게 할 필요는 없겠죠. 필요한 만큼, 자의식만큼 열심히 헌신하면 되는 것이라고 생각합니다.(레프트21 관련자들이 기술 진보를 노는 데 활용한다는 말이 아닌 건 아시겠죠?)
발달한 기술을 적용하지 못해서, 좀 더 편하게 할 수 있는 데 쓸데 없는 노동력을 들이는 경우를 보면 안타깝기 그지없습니다. 그만큼 사회진보를 위해 일할 시간이 줄어드는 것이라는 생각이 드니까요.
직결되는 것은 아닙니다만, 옛 신문을 검색하려고 하는데, 검색할 때마다 4~7초씩 화면이 뜨기를 기다리는 수많은 사람들을 생각하면 끔찍할 뿐입니다. 사회진보를 위해 일하는 많은 사람들의 몇 초나마 아낄 수 있도록 하는 데 제가 기여했다면 좋은 일이겠지요.
레프트21 웹사이트의 효율화는 이런 생각을 하면서 진행하고 있습니다. 더 많은 부분을 쉽고 편하게 만들어, 사회 진보를 위해 일하는 많은 사람들이 불편함 없이 자신의 일에 집중할 수 있도록 하는 것이 기술 분야에서 저의 꿈입니다. 이상.