구글 아날리틱스, 검색 유입을 분명히 감지하기
구글 아날리틱스는 구글에서 무료로 제공하는 홈페이지 통계분석 프로그램이다.
트래픽소스 부분은 정말 도움이 된다. 어떤 링크를 타고 우리 홈페이지로 들어왔는지 알 수 있게 해 주기 때문이다.
고급 세그먼트는, 내가 알고싶은 트래픽만 따로 분석할 수 있게 해주기 때문에 큰 도움이 된다.
워낙 도움되는 기능이 많아서 일일이 설명하기 힘들고… ㅋ
어쨌든, 직관적으로 가장 도움이 되는 부분은, 지금 우리 홈페이지 방문자들이 어떤 경로로 들어오는지 알려 주는 ‘트래픽 소스 개요’와 ‘트래픽 소스’의 ‘검색 엔진’ 부분이다.
검색 유입
웹 기술이 발달할수록, 검색의 중요성이 높아지고 있다. 오랜 시간동안 높은 접근성을 유지시킬 수 있는 웹이라는 환경에서, 검색은 자료에 접근할 수 있도록 해 주는 통로가 된다.
대표적인 예는 신문기사인데, 웹이 없는 상황에서였다면, 예전 기사를 보기 위해 도서관에 가서 예전 신문들을 뒤적거려야 했을 것이다. 웹에 기사들이 다 올라온 이후부터 상황이 바뀌었다. 신문 기사를 검색하는 것은 너무나 쉬워졌다.
나는 <레프트21> 홈페이지를 기획하면서 이 점을 가장 중요한 과제로 보았다. 따라서 우리 홈페이지가 검색에 잘 노출될 수 있도록 신경쓰는 데 혼신의 힘을 기울였다.
그리고 지금, 창간부터 8개월이 지났다. 이번 1주일의 검색 유입량은 내 입을 벌어지게 만든다.
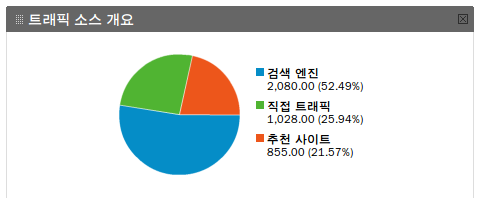
검색 엔진을 통한 유입이 절반을 넘어섰다. 3월 중순의 검색 유입은 18퍼센트였다. 2.88배 증가한 것이다.
검색 유입 트래픽 모두 감지하기
그런데 구글 아날리틱스에서 검색 유입을 확실히 알기 위해 한 가지 작업이 필요했다.
구글 아날리틱스가 자동으로 모든 검색엔진의 트래픽을 ‘검색 엔진’ 파트로 분류해 주지 않는다는 사실을 알게 된 것이다.
그래서 구글 아날리틱스의 소스를 다음처럼 변경했다. 이렇게 변경을 해 줘야 검색 유입이 정확히 얼마나 되는지 분명히 분석할 수 있게 된다.(이 소스로 변경하기 전의 검색 유입량은 고급 세그먼트를 사용해서 해결하긴 했다.)
<script type="text/javascript">
var gaJsHost = (("https:" == document.location.protocol) ? "https://ssl." : "http://www.");
document.write(unescape("%3Cscript src='" + gaJsHost + "google-analytics.com/ga.js' type='text/javascript'%3E%3C/script%3E"));
</script>
<script type="text/javascript">
try {
var pageTracker = _gat._getTracker("고유ID-자기걸로쓰면된다");
pageTracker._clearOrganic();
pageTracker._addOrganic("naver.com","query");
pageTracker._addOrganic("search.naver.com","query");
pageTracker._addOrganic("daum.net","q");
pageTracker._addOrganic("nate.com","q");
pageTracker._addOrganic("empas.com","q");
pageTracker._addOrganic("google.com","q");
pageTracker._addOrganic("google.co.kr","q");
pageTracker._addOrganic("google.co.jp","q");
pageTracker._addOrganic("google.cn","q");
pageTracker._addOrganic("google.ca","q");
pageTracker._addOrganic("google.de","q");
pageTracker._addOrganic("images.google.co.kr","q");
pageTracker._addOrganic("images.google.com","q");
pageTracker._addOrganic("paran.com","Query");
pageTracker._addOrganic("yahoo.com","p");
pageTracker._trackPageview();
} catch(err) {}
</script>
보면 줄이 꽤 많아졌다. 트래픽 소스를 보면서 검색엔진인데 단순 링크 유입으로 분류된 트래픽 소스를 다 찾아냈다. 그리고 키워드에 사용되는 매개변수를 분석했다. 그 결과 레프트21에 검색으로 유입되는 주소가 저렇게 많다는 것을 발견하게 됐다.
특히, 구글 아날리틱스는 네이버와 다음, 네이트의 검색 유입을 초기에 명확히 인지하지 못한다. 세 회사가 우리나라 1~3등 검색 회사므로 이건 심각한 문제다. 따라서 이들이 들어있는 이 네 줄은 반드시 적어 줘야 한다.
pageTracker._addOrganic("naver.com","query");
pageTracker._addOrganic("search.naver.com","query");
pageTracker._addOrganic("daum.net","q");
pageTracker._addOrganic("nate.com","q");
또한, 검색 유입을 사용자가 직접 입력하겠다는 의미로 다음 선언을 써줘야 한다. 누락하지 말자.
pageTracker._clearOrganic();
온전한 소스를 보면서 찬찬히 뜯어보면 다 알 수 있을 것이다. 그럼…